The “Big Data” Trap
Here is the math that kept me up at night: Consider a modest experiment with 100 blueberry plots, imaged at five time points. If each plant has roughly 200 leaves, that is 100,000 leaf instances.
If I were to manually annotate those (identifying the relevant 1% of the dataset, counting them, and outlining them) and if I was incredibly fast (1 second per leaf), that single experiment would cost me 3.5 days of continuous, non-stop clicking. No coffee breaks. No sleep. Just clicking.
I decided there had to be a better way. I didn’t want to spend my internship drawing polygons. I wanted to spend it building something that would draw polygons for me.
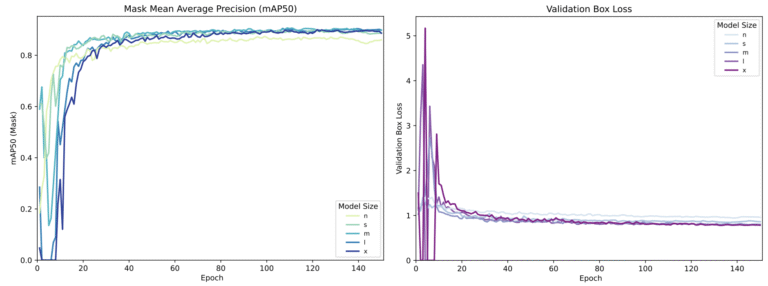
Enter PhenoSelect: a modular deep learning pipeline I developed to automate leaf segmentation and trait classification.
Why Not Use Existing Tools?
Before I started writing Python scripts, I looked at what was already out there. The landscape of phenotyping software is vast, but it tends to be polarized.
On one side, you have highly automated tools like ARADEEPOPSIS. It uses semantic segmentation to classify pixels as “healthy,” “senescent,” or “background”. This is great for whole-plant stress quantification, but it doesn’t distinguish one overlapping leaf from another. It gives you a “blob” of plant tissue, not a count of leaves or their individual sizes.
On the other side, you have user-friendly web apps that run instance segmentation. These can outline leaves beautifully, but they often lack the second critical step: classification. They tell you “This is a leaf,” but they can’t tell you “This is a fully visible, healthy leaf suitable for spectral analysis.”
I needed a hybrid. I needed a tool that could:
Segment: Find every individual leaf instance (Instance Segmentation).
Classify: Tell me if that leaf is healthy, mature, or fully exposed (Classification).
Scale: Process thousands of images with the scalability required for HTPP data.
… aaaand I also really want to learn more about neural networks and practical applications of it, so I closed my eyes and decided that this would be the best approach.